I've discussed why this kind of thing is problematic in a previous blogpost, but perhaps a figure will help. The point is that in a large sample you can have a statistically strong association between a condition such as dyslexia and a genetic variant, but this does not mean that you can predict who will be dyslexic from their genes.
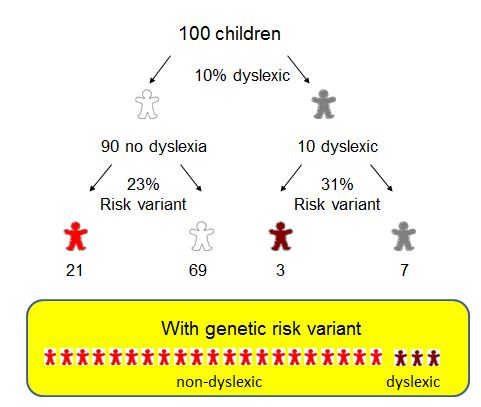 | |
| Proportions with risk variants estimated from Scerri et al (2011) |
So what about the results from the latest Yale press release? Do they allow for more accurate identification of dyslexia on the basis of genes? In a word, no. I was pleased to see that the authors reported the effect sizes associated with the key genetic variants, which makes it relatively easy to estimate their usefulness in screening. In addition to identifying two sequences in DCDC2 associated with risk of language or reading problems, the authors noted an interaction with a risk version of another gene, KIAA0319, such that children with risk versions in both genes were particularly likely to have problems. The relevant figure is shown here.
Update: 30th December 2014 - The authors have published an erratum indicating that Figure 3A was wrong. The corrected and original versions are shown below and I have amended conclusions in red.
 |
| Corrected Fig 3A from Powers et al (2013) |
 |
| Original Fig 3A from Powers et al (2013) |
There are several points to note from this plot, bearing in mind that dyslexia or SLI would normally only be diagnosed if a child's reading or language scores were at least 1.0 SD below average.
- For children who have either KIAA0319 or DCDC2 risk variants, but not both, the average score on reading and language measures is
at mostno more than 0.1 SD below average at most. - For those who have both risk factors together, some tests give scores that are from 0.2 to 0.3 SD below average
, but this is only a subset of the reading/language measures. On nonword reading, often used as a diagnostic test for dyslexia, there is no evidence of any deficit in those with both risk versions of the genes.On the two language measures, the deficit hovers around 0.15 SD below the mean. The tests that show the largest deficits in those with two risk factors are measures of IQ rather than reading or language. Even here, the degree of impairment in those with two risk factors together indicates that the majority of children with this genotype would not fall in the impaired range.- The number of children with the two risk factors together is very small, around 2% of the population.
*It is unclear to me whether the Yale University Press Office are actively involved in gatecrashing Research Blogging, or whether this is just an independent 'blogger' who is recycling press releases as if they are blogposts.
Reference
Powers, N., Eicher, J., Butter, F., Kong, Y., Miller, L., Ring, S., Mann, M., & Gruen, J. (2013). Alleles of a Polymorphic ETV6 Binding Site in DCDC2 Confer Risk of Reading and Language Impairment The American Journal of Human Genetics DOI: 10.1016/j.ajhg.2013.05.008
Scerri, T. S., Morris, A. P., Buckingham, L. L., Newbury, D. F., Miller, L. L., Monaco, A. P., . . . Paracchini, S. (2011). DCDC2, KIAA0319 and CMIP are associated with reading-related traits. Biological Psychiatry, 70, 237-245. doi: 10.1016/j.biopsych.2011.02.005












Thanks for this. We always need to separate the scientific wheat from the chaff.
ReplyDeleteThank you Dorothy for this post. I’ll take the opportunity to express some concerns I have around this paper.
ReplyDeleteIt describes an impressive amount of work but my feeling was that the results were pretty inconclusive.
Most of the story is around the association with two haplotypes. However, in my opinion the analysis has some problems:
- the associated haplotypes are rare and it is very common in quantitative analysis to observe this sorts of associations with rare haplotypes by random effect.
- cases and controls are define in a very arbitrary way. By setting the severity level so low (below -2sd) the number of cases is very small (n=89) and if the haplotypes have a frequency of 2 or 3 % we are actually looking at very few informative cases, emphasising even more the problem described at the point above. In contrast the number of controls is quite large and it looks to me this is because controls are everybody else (i.e. everybody scoring above -2 sd… So people scoring 1.99 sd below the mean have been considered controls!). This is a curious choice, because one of the problems in case/controls analysis is that often controls with no phenotypes are used accepting the limitation that some of the controls will actually be cases. But in this study, where phenotypes are available, the controls should really be selected more carefully. I would believe more the data if the cases would have been a larger and less severe group and if the controls were at least scoring above the mean.
-assuming these haplotypes are genuinely associated, the story goes on linking these two haplotypes with the alleles around the deletion locus (I dont want to call it READ1 yet). The authors says that everybody scoring positive for the associated haplotypes were sequenced at the DCDC2 deletion locus and they found that most of people showed allele 5 and 6 of a polymorphic site. This is not surprising given the LD in the region and is not enough to claim any functional effect. For example, how do we know that while the associated haplotypes often are linked with allele 5 and 6 at the deletion locus the vice versa is also true? In other words, these analysis does not exclude that allele 5 and 6 might be more frequent than the associated haplotypes and to come to any conclusion they should be tested for association in the entire sample set and ideally in a replication cohort. I appreciate it would be lots of work, but we cannot really believe the assumption made otherwise. As the authors say in the introduction this locus was already been tested in other populations so why not testing this hypothesis in these samples available to the authors?
-Regardless, as I am reading the story so far, the author seems to suggested that the haplotypes associate to poor reading are linked to allele5 and 6 that might be functional. So the associated haplotype are detecting the signal of allele5 and 6. So I would expect the next step to be a demonstration that allele 5 and 6 are actually functional. However, we are shown that the transcription factor ETV6 is binding to this locus (regardless of the allelic status). While this might be an interesting observation, I am not sure what does this tell us about the functional mechanism that would explain the effect of the associated haplotypes and the allele5/6. What I would like to see is whether having the associated haplotype changes affinity for this DNA/transcription factor interaction. As we are learning from the ENCODE project the genome contains lots of functional element and it is common to see that genetic associations are phisically located next to these elements, but if we cannot show that associated ALLELES have some functional effects on such elements (e.g. changing binding affinity to transcription factors) any conclusions remain speculative.....as most of this paper.
Is there general agreement now that dyslexia exists?
ReplyDeleteI've been relying on the findings of a research survey by the National research and Development Centre for adult literacy and numeracy.
This concludes that "There are many definitions of dyslexia but no consensus. Some definitions are purely descriptive, while others embody causal theories. It appears that ‘dyslexia’ is not one thing but many, in so far as it serves as a conceptual clearing-house for a number of reading skills deficits and difficulties, with a number of causes.
There is no consensus, either, as to whether dyslexia can be distinguished in practice from other possible causes of adults’ literacy difficulties. Many ‘signs of dyslexia’ are no less characteristic of non-dyslexic people with reading skills deficits. In our present state of knowledge, it does not seem to be helpful for teachers to think of some literacy learners as ‘dyslexics’ and of others as ‘ordinary poor readers’."
See http://www.nrdc.org.uk/projects_details.asp?ProjectID=75
But perhaps I should revise my view...
There's no support for the idea of a syndrome, but plenty of evidence that many children have unexplained problems in learning to read. And there's also good evidence that genes are implicated in determining which children are affected - but it's complicated, with most experts concluding that risk of poor reading is determined by a mix of many small genetic influences plus environmental factors.
DeletePlease see this post for a more detailed discussion of the issues re terminology:
http://deevybee.blogspot.co.uk/2010/12/whats-in-name.html
Thanks Dorothy and Silvia for your excellent analysis. This is my paper for our journal club today! I was alerted to the article by the overexcited press release a couple of weeks ago and have been following the story with interest.
ReplyDelete"However, the results indicate that, far from indicating translational potential for diagnosis and treatment, genetic effects are subtle and unlikely to be useful for this purpose."
ReplyDeleteIf I'm interpreting it correctly, that statement seems as overhyped as the one you're exposing. Where does this particular paper show that our current lack of knowledge poses a theoretical challenge to the idea that genes qua genes are unlikely to be useful for diagnosis and treatment?
Hi Dorothy,
ReplyDeleteI watched your Lecture “Can studying the brain help us understand dyslexia?” on YouTube. I tend to agree with your assertion that being dyslexic is most likely a reading/writing shortcoming, just as non-dyslexics have other shortcomings. I also believe that as a dyslexic (or poor reader/writer), I too have strengths that some good readers do not.
I hear a lot that dyslexics are gifted in other areas, especially with visuospatial ability. Do you think this is a characteristic of the majority of dyslexics or is it just a random example of a possible strength? We are led to believe now that many of the great thinkers were dyslexic. I want to believe this, but I wonder if science backs this up.
So in short I’m wondering if there is any hard evidence to support the theory that dyslexics are more advanced on average than non-dyslexics in areas outside of their disability.
Thanks so much for your research.
I've not looked at the evidence in detail, but my impression is that the results you get depends on how you select your sample.
DeleteThere are some epidemiological samples with children, and I don't think any of these show that poor readers of normal IQ have compensating talents. It's possible, of course, that nobody's measured the right things, but the evidence for superior visuospatial skills is lacking. In any individual dyslexic, it's likely that visuospatial skills will be better than verbal skills , because weaker verbal skills are associated with dyslexia. But I know of no research showing that the distribution of visuospatial skills is superior in dyslexics,compared to nondyslexics, if the sample is selected by general population screening.
Some researchers work with adult samples, and these are nearly always recruited from those who are successful - either university students, or people who have made a success of life through other routes. It's likely that these people with have some unusual talent: if not, how would they have done so well in life, despite dyslexia? They cannot, however, be regarded as representative of the dyslexic population as a whole.
Let me be clear, as this can be a highly contentious topic. It's beyond doubt that some people with dyslexia have considerable talents in other domains. I do not, however, think it's a general feature of dyslexia - rather, I think we notice the exceptionally talented cases more because they tend to be successful, and they put the lie to the idea that being dyslexic necessarily means you will be a failure.
This is not something I've researched myself, and I've not read widely on this topic, so I'd be interested to hear of any evidence to the contrary.